前言: 📝📝此专栏文章是专门针对网络爬虫基础,欢迎免费订阅!
📝📝第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一, 第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八,欢迎阅读!
🎈🎈欢迎大家一起学习,一起成长!!
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。

Python 正则表达式
Python 正则表达式是一种用于匹配、搜索、替换文本中模式的工具。它使用特定的语法来描述一些规则,这些规则可以用于匹配文本中的某些模式。通过使用正则表达式,可以快速地搜索和处理大量的文本数据,从而节省时间和精力。
- 在 Python 中,正则表达式可以通过 re 模块进行操作。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
- re 模块使 Python 语言拥有全部的正则表达式功能。
- compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
- re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
re.match() 函数
re.match() 函数是 Python中用于匹配字符串开头的函数。该函数尝试从字符串的开头开始匹配一个正则表达式模式,如果匹配成功,则返回一个匹配对象,否则返回 None。
python">re.match(pattern, string, flags=0)
参数说明:
示例代码:
python">import re
# 匹配一个以 hello 开头的字符串
pattern = r'hello'
string = 'hello world'
match_obj = re.match(pattern, string)
if match_obj:
print('匹配成功')
else:
print('匹配失败')
输出结果为:

我们可以使用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。
参数说明:
span()起始位置
group()返回获取参数。
代码展示:
python">import re
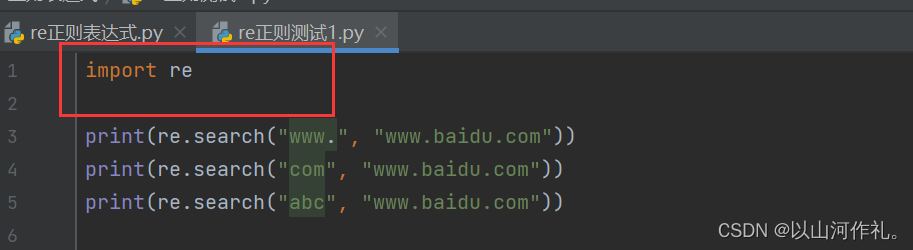
print(re.match('www', 'www.baidu.com').span()) # 在起始位置匹配 (0, 3)
print(re.match('com', 'www.baidu.com')) # 不在起始位置匹配 None
运行结果:

re.search方法
re.search方法是Python中re模块的一个函数,用于在字符串中搜索匹配正则表达式的第一个位置,并返回一个包含匹配信息的Match对象。如果没有匹配到,则返回None。
该方法的语法如下:
python">re.search(pattern, string, flags=0)
以下是一个简单的示例,演示如何使用re.search方法:
python">import re
# 定义一个正则表达式
pattern = r'hello'
# 定义一个字符串
string = 'hello, world!'
# 在字符串中搜索匹配项
match_obj = re.search(pattern, string)
if match_obj:
print('匹配成功!')
else:
print('匹配失败!')
输出结果为:
匹配成功!
在这个示例中,我们定义了一个正则表达式模式"hello",然后在字符串"hello,world!“中搜索匹配项。由于该字符串包含"hello”,因此re.search方法返回了一个匹配对象。最后,我们检查匹配对象是否存在,以确定匹配是否成功。
re.match与re.search的区别
re.match和re.search都是Python中re模块中的函数,它们的主要区别在于匹配的位置不同。
re.match只会从字符串的开头开始匹配,如果在开头没有匹配到,则返回None。而re.search则会搜索整个字符串,只要找到第一个匹配项,就会返回一个匹配对象。
以下是一个简单的示例,演示re.match和re.search的区别:
python">import re
# 定义一个正则表达式
pattern = r'hello'
# 定义一个字符串
string = 'hello, world!'
# 使用re.match进行匹配
match_obj = re.match(pattern, string)
if match_obj:
print('re.match匹配成功!')
else:
print('re.match匹配失败!')
# 使用re.search进行匹配
match_obj = re.search(pattern, string)
if match_obj:
print('re.search匹配成功!')
else:
print('re.search匹配失败!')
输出结果为:
re.match匹配成功!
re.search匹配成功!
在这个示例中,我们定义了一个正则表达式模式"hello",然后在字符串"hello,
world!“中使用re.match和re.search进行匹配。由于"hello"出现在字符串的开头,因此re.match和re.search都返回了一个匹配对象,表示匹配成功。但是,如果我们将字符串改为"world,
hello!”,则re.match将返回None,因为"hello"不在字符串的开头。
re.compile 函数
在Python中,re.compile()函数是用于将正则表达式编译成一个正则表达式对象的函数。编译后的正则表达式对象可以被多次使用,可以提高程序的效率。
re.compile()函数的语法如下:
python">re.compile(pattern, flags=0)
参数说明:
pattern:要编译的正则表达式flags:可选参数,用于指定匹配模式,具体参数参考re模块的文档
示例代码:
python">import re
# 编译正则表达式
pattern = re.compile(r'\d+')
str = 'hello 123 world 456'
# 使用正则表达式对象进行匹配
result = pattern.findall(str)
print(result)
输出结果:
['123', '456']
上面的代码中,我们先使用re.compile()函数将正则表达式编译成一个正则表达式对象,然后使用该对象的findall()方法进行匹配。这样可以提高程序的效率,特别是在需要多次使用同一个正则表达式时。
检索和替换
Python中可以使用re模块来进行正则表达式的检索和替换。
python">re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
检索:
使用re.search()函数可以在字符串中查找匹配某个正则表达式的子串,返回一个match对象。
示例代码:
python">import re
str = "The quick brown fox jumps over the lazy dog."
match = re.search(r'fox', str)
if match:
print("找到了:", match.group())
else:
print("没找到")
输出结果:
找到了: fox
替换:
使用re.sub()函数可以将字符串中匹配某个正则表达式的子串替换成指定的字符串。
示例代码:
python">import re
str = "The quick brown fox jumps over the lazy dog."
new_str = re.sub(r'fox', 'cat', str)
print("替换前:", str)
print("替换后:", new_str)
输出结果:
替换前: The quick brown fox jumps over the lazy dog.
替换后: The quick brown cat jumps over the lazy dog.
findall
findall是 Python 中 re 模块提供的一个函数,用于在字符串中找到所有匹配正则表达式的子串,并返回一个列表。
它的语法如下:
python">re.findall(pattern, string, flags=0)
- 其中,
pattern是正则表达式,string是要匹配的字符串,flags是可选的标志参数。 findall函数返回一个包含所有匹配子串的列表,如果没有匹配到任何子串,则返回一个空列表。
示例代码:
python">import re
pattern = re.compile(r'(\d+) (\d+)') # 查找数字 有助于一个表达式在不同的情况下测试
result1 = pattern.findall('123 abc 456')
result2 = pattern.findall('123 456 abc 456 789')
print(result1)
print(result2)
输出结果:

re.finditer
re.finditer是 Python 中 re 模块提供的一个函数,用于在字符串中找到所有匹配正则表达式的子串,并返回一个迭代器。
它的语法如下:
python">re.finditer(pattern, string, flags=0)
- 其中,
pattern是正则表达式,string是要匹配的字符串,flags是可选的标志参数。 finditer函数返回一个迭代器,可以迭代得到所有匹配子串的 MatchObject
对象。如果没有匹配到任何子串,则返回一个空迭代器。- 与
findall不同的是,finditer
返回的是迭代器,可以逐个获取匹配的结果,而不是一次性获取全部结果。这在匹配大量文本时可以节省内存。
re.split
re.split是 Python 中 re 模块提供的一个函数,用于按照正则表达式指定的模式分割字符串,并返回一个列表。
它的语法如下:
python">re.split(pattern, string, maxsplit=0, flags=0)
- 其中,
pattern是正则表达式,string是要分割的字符串,maxsplit是指定最大分割次数,flags
是可选的标志参数。 split函数返回一个列表,包含所有分割后的子串。如果没有匹配到任何子串,则返回一个包含原字符串的列表。- 与 Python 内置的
split函数不同的是,re.split
可以按照正则表达式指定的模式进行分割,例如按照空格、逗号、分号等进行分割,而不仅仅是按照固定的字符进行分割。同时,re.split还支持指定最大分割次数,以控制分割的结果。
正则表达式模式
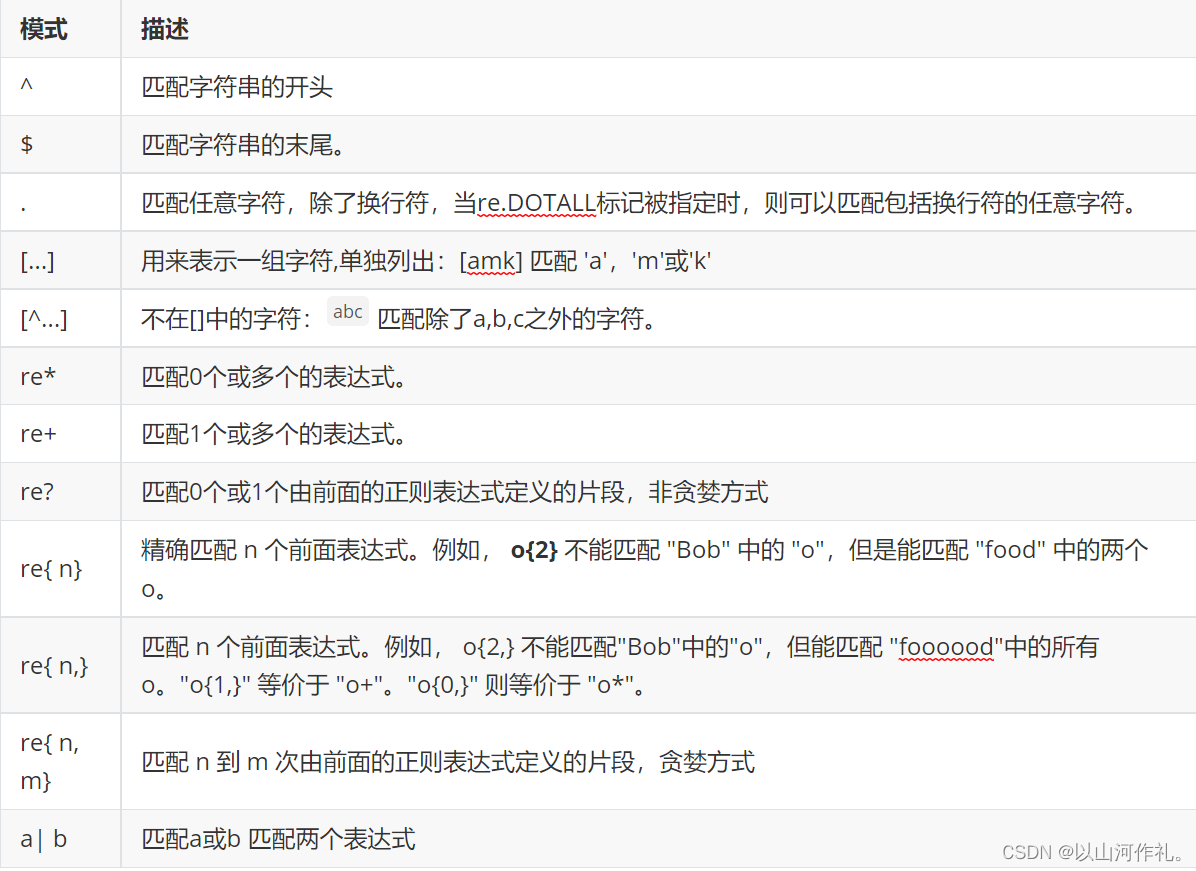
模式字符串使用特殊的语法来表示一个正则表达式:
- 字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
- 多数字母和数字前加一个反斜杠时会拥有不同的含义。
- 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
- 反斜杠本身需要使用反斜杠转义。
- 由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r’\t’,等价于 ‘\t’)匹配相应的特殊字符。
- 下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
常见的字符类正则模式
字符类正则模式用于匹配一组特定的字符。以下是常见的字符类正则模式:
1. [abc]:匹配字符 a、b 或 c 中的任意一个。
2. [^abc]:匹配除了字符 a、b 和 c 以外的任意字符。
3. [a-z]:匹配任意小写字母。
4. [A-Z]:匹配任意大写字母。
5. [0-9]:匹配任意数字。
6. [a-zA-Z]:匹配任意字母。
7. [a-zA-Z0-9]:匹配任意字母或数字。
8. [\s]:匹配任意空白字符,包括空格、制表符、换行符等。
9. [\S]:匹配任意非空白字符。
10. [\d]:匹配任意数字,等同于 [0-9]。
11. [\D]:匹配任意非数字字符。
12. [\w]:匹配任意字母、数字或下划线字符。
13. [\W]:匹配任意非字母、数字或下划线字符。
正则表达式模式量词
正则表达式模式量词用于表示匹配次数,常用的量词包括:
python">1. *:匹配前面的模式零次或多次,等效于{0,};
2. +:匹配前面的模式一次或多次,等效于{1,};
3. ?:匹配前面的模式零次或一次,等效于{0,1};
4. {n}:匹配前面的模式恰好n次;
5. {n,}:匹配前面的模式至少n次;
6. {n,m}:匹配前面的模式至少n次,但不超过m次。
例如,正则表达式模式\d{3,5}表示匹配3到5个数字,正则表达式模式a+b*表示匹配一个或多个a,后面跟零个或多个b。
正则表达式举例
python">1. 匹配邮箱地址的模式:^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$
2. 匹配手机号码的模式:^1[3456789]\d{9}$
3. 匹配身份证号码的模式:^\d{17}[\dXx]|\d{15}$
4. 匹配IP地址的模式:^((\d{1,2}|1\d{2}|2[0-4]\d|25[0-5])\.){3}(\d{1,2}|1\d{2}|2[0-4]\d|25[0-5])$
5. 匹配URL地址的模式:^[a-zA-Z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$
6. 匹配汉字的模式:^[\u4e00-\u9fa5]{0,}$
7. 匹配中文和英文的模式:^[\u4e00-\u9fa5a-zA-Z]+$
8. 匹配邮政编码的模式:^[1-9]\d{5}$
9. 匹配日期的模式:^\d{4}-\d{1,2}-\d{1,2}$
10. 匹配时间的模式:^(0?\d|1\d|2[0-3]):[0-5]\d(:[0-5]\d)?$
🍁 🍁今日学习笔记到此结束,感谢你的阅读,如有疑问或者问题欢迎私信,我会帮忙解决,如果没有回,那我就是在教室上课,抱歉。
🍂🍂🍂🍂