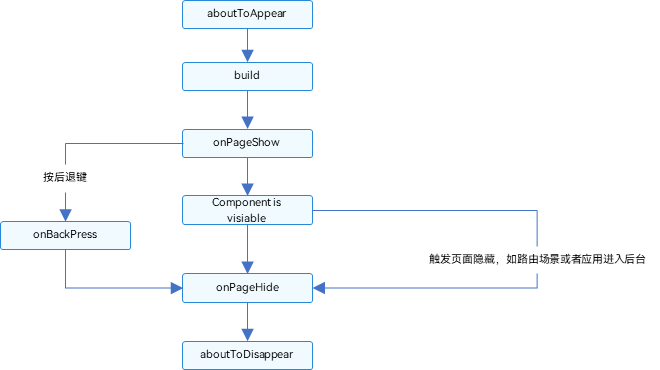
使用Go进行开发的最大优势之一是其标准库。与Python类似,Go也采取了“内置电池”的理念,提供了构建应用程序所需的许多工具。由于Go是一种相对较新的语言,它附带了一个专注于现代编程环境中遇到的问题的库。
我们无法涵盖所有标准库包,所幸也不需要,因为有许多优秀的信息源可以了解标准库,比如官方文档。我们将重点关注几个最重要的包及其设计和用法来演示地道Go语言的基本原则。一些包(errors、sync、context、testing、reflect和unsafe)在各自的章节中进行过介绍。在本章中,我们将学习Go对I/O、时间、JSON和HTTP的内置支持。
I/O和它的小伙伴们
要使程序有价值,它需要能读取和写出数据。Go的输入/输出理念的核心在io包中有体现。特别是,在该包中定义的两个接口可能是Go中第二和第三最常用的接口:io.Reader和io.Writer。
注:第一名是谁呢?自然是error,我们已经在错误处理一章中学习过了。
io.Reader和io.Writer各自定义了一个方法:
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}io.Writer接口中的Write方法接收一个字节切片参数,位于接口的实现中。它返回写入的字节数,如果出现错误则返回错误信息。io.Reader中的Read方法更有趣。它不是通过返回参数来返回数据,而是将一个切片作为入参传入实现,并进行修改。最多会将len(p)个字节写入到该切片中。该方法返回写入的字节数。这可能看起来有点奇怪。读者期望的可能是:
type NotHowReaderIsDefined interface {
Read() (p []byte, err error)
}标准库中定义io.Reader的方式是有原因的。我们来编写一个函数说明如何使用io.Reader方便大家理解:
func countLetters(r io.Reader) (map[string]int, error) {
buf := make([]byte, 2048)
out := map[string]int{}
for {
n, err := r.Read(buf)
for _, b := range buf[:n] {
if (b >= 'A' && b <= 'Z') || (b >= 'a' && b <= 'z') {
out[string(b)]++
}
}
if err == io.EOF {
return out, nil
}
if err != nil {
return nil, err
}
}
}有三点需要注意。首先,我们只需创建一次缓冲区,在每次调用r.Read.时复用它即可。这样我们能够使用单次内存分配读取可能很大的数据源。如果Read方法返回[]byte,那么每次调用都需要重新分配内存。每次分配最终都会出现在堆上,这会给垃圾回收器带来很大的工作量。
如果我们想进一步减少分配,可以在程序启动时创建一个缓冲池。然后在函数开始处从池中获取一个缓冲区,结束时归还。通过将切片传递给io.Reader,内存分配就由开发人员所控制。
其次,我们使用r.Read返回的n值来了解有多少字节被写入缓冲区,并遍历buf切片的子切片,处理所读取的数据。
最后,在r.Read返回的错误是io.EOF时,对r的读取就结束了。这个错误有点奇怪,因为它实际上并不是一个错误。它表示io.Reader中没有剩余可读取的内容。在返回io.EOF时,我们结束处理并返回结果。
io.Reader的Read方法有一个特别之处。在大多数情况下,在函数或方法具有错误返回值时,我们在尝试处理非错误返回值之前先检查错误。但在Read的情况中情况相反,因为在数据流结束或意外情况触发错误之前可能已经返回了一些字节,所以操作相反。
注:如果意外到达了
io.Reader的末尾,会返回一个另一个哨兵错误(io.ErrUnexpectedEOF)。注意它以字符串Err开头,表示这是一种意料外的状态。
因为io.Reader和io.Writer接口非常简单,可以用多种方式进行实现。我们可以使用strings.NewReade函数通过字符串创建一个io.Reader:
s := "The quick brown fox jumped over the lazy dog"
sr := strings.NewReader(s)
counts, err := countLetters(sr)
if err != nil {
return err
}
fmt.Println(counts)我们在接口是类型安全的鸭子类型中讨论过,io.Reader 和io.Writer的实现通常以装饰器模式链接。由于countLetters依赖于io.Reader,我们可以使用完全相同的countLetters函数来计算gzip压缩文件中的英文字母。首先编写一个函数,给定文件名时,返回*gzip.Reader:
func buildGZipReader(fileName string) (*gzip.Reader, func(), error) {
r, err := os.Open(fileName)
if err != nil {
return nil, nil, err
}
gr, err := gzip.NewReader(r)
if err != nil {
return nil, nil, err
}
return gr, func() {
gr.Close()
r.Close()
}, nil
}这个函数演示了实现io.Reader合适的封装类型。我们创建了一个*os.File(符合io.Reader接口),在确保其为有效之后,将它传递给gzip.NewReader函数,该函数返回一个*gzip.Reader实例。如果有效,我们返回*gzip.Reader和一个关闭器闭包,当调用它时可以恰如其分地清理我们的资源。
因*gzip.Reader实现了io.Reader,我们可以像之前使用的*strings.Reader一样使其与countLetters一起使用:
r, closer, err := buildGZipReader("my_data.txt.gz")
if err != nil {
return err
}
defer closer()
counts, err := countLetters(r)
if err != nil {
return err
}
fmt.Println(counts)因为我们有用于读取和写入的标准接口,在io包中有一个标准函数用于从io.Reader拷贝至io.Writer,即io.Copy。还有其他标准函数可为已有的io.Reader和io.Writer实例添加新功能。其中包括:
io.MultiReader返回一个从多个io.Reader实例逐一读取的io.Reader。io.LimitReader返回一个仅从提供的io.Reader中读取指定字节数的io.Reader。io.MultiWriter返回一个同时向多个io.Writer实例写入的io.Writer。
其它标准库的包提供了各自的类型和函数,用于处理io.Reader和io.Writer。我们已学习过一些,但还有很多。有压缩算法、存档、加密、缓冲、字节切片和字符串。
在io中还定义了其他单个方法的接口,如io.Closer和io.Seeker:
type Closer interface {
Close() error
}
type Seeker interface {
Seek(offset int64, whence int) (int64, error)
}io.Closer接口由像os.File这样需要在读取或写入完成时进行清理的类型实现。通常,使用defer调用Close函数:
f, err := os.Open(fileName)
if err != nil {
return nil, err
}
defer f.Close()
// use f警告: 如果在循环中打开资源,请不要使用
defer,因为它在函数退出时才会执行。应该在循环迭代结束之前调用Close方法。如果存在可能导致退出的错误,你也必须在该处调用Close方法。
io.Seeker接口用于对资源进行随机访问。whence参数的有效值为io.SeekStart、io.SeekCurrent和io.SeekEnd这些常量。本应使用自定义类型来更清晰地表示,但出现了一个令人吃惊的设计失误,whence的类型是int。
io包中定义了组合这四个接口各种组合。它们有io.ReadCloser、io.ReadSeeker、io.ReadWriteCloser、io.ReadWriteSeeker、io.ReadWriter、io.WriteCloser和io.WriteSeeker。使用这些接口来指定函数期望对数据的操作。例如,不单使用os.File作为参数,而是使用接口来明确指定函数如何处理参数。这不仅会使函数更通用,还会让开发者的意图更加清晰。此外,如果你正在编写自己的数据源和接收端,要保持代码与这些接口兼容。总体来说,尽量创建像io中定义的接口一样简单和解耦的接口。它们展示了简单抽象的强大。
ioutil包提供了一些简单的实用工具,用于将整个io.Reader实现一次性读入字节切片,读取和写入文件以及处理临时文件等。ioutil.ReadAll、ioutil.ReadFile和ioutil.WriteFile函数可处理小型数据源,但对于大数据源最好使用bufio包中的Reader、Writer和Scanner来做处理。
ioutil中更巧妙的一个函数演示了如何为Go类型添加方法的模式。如果一个类型实现了io.Reader但没有实现io.Closer的类型(比如strings.Reader),并且需要将其传递给接收io.ReadCloser的函数,可以将io.Reader传递给ioutil.NopCloser函数,会得到一个实现了io.ReadCloser的类型。其实现非常简单:
type nopCloser struct {
io.Reader
}
func (nopCloser) Close() error { return nil }
func NopCloser(r io.Reader) io.ReadCloser {
return nopCloser{r}
}在需要为类型添加额外的方法实现接口时,可以使用这种嵌入类型模式。
注:
ioutil.NopCloser函数违反了不从函数返回接口的一般规则,但它是一个用于确定不会改变的接口的简单适配器,因为它来自标准库。
time
和大部分编程语言一样,Go标准库包含对时间支持,位于time包中。有两种表示时间的主要类型,time.Duration和time.Time。
时间段由time.Duration表示,其类型为int64。Go可以表示的最小时间单位是一纳秒,但time包定义了time.Duration类型的常量来表示纳秒、微秒、毫秒、秒、分钟和小时。例如,可以用以下方式表示2小时30分钟的时长:
d := 2 * time.Hour + 30 * time.Minute // d is of type time.Duration这些常量使得time.Duration既易读又类型安全。它们展示了对带类型常量很好的使用。
Go 定义了一个易理解的字符串格式,由一系列数字组成,可以用time.ParseDuration函数解析为time.Duration。如标准库文档所述:
时长字符串是有符号的十进制数序列,可带小数及后接单位,例如 "300ms"、"-1.5h" 或 "2h45m"。有效的时间单位包括 "ns"、"us"(或 "µs")、"ms"、"s"、"m"、"h"。
- Go 标准库文档
time.Duration上定义了多个方法。它实现了fmt.Stringer接口,并通过 String 方法返回格式化的时长字符串。它有获取小时、分钟、秒、毫秒、微秒或纳秒等数值的方法。Truncate 和 Round 方法将time.Duration截取或四舍五入为指定的time.Duration单位。
某个时间由time.Time类型表示,包含时区。可以使用 time.Now函数获取当前时间。它返回一个本地时区的time.Time实例。
小贴士:
time.Time实例包含时区信息,因此不应使用==来检查两个time.Time实例是否对应同一时刻。而应使用Equal方法,该方法会校正时区。
time.Parse函数将字符串转换为time.Time,而Format方法将time.Time转换为字符串。尽管 Go 通常采用曾经运行良好的想法,但它使用自有的日期和时间格式化语言。将日期和时间格式化为 "2006年1月2日 下午3点04分05秒 MST(山区标准时间)" 来指定格式。
注:为什么选择这个日期?因为其中的每个部分依次代表了数字 1 到 7,即 01/02 03:04:05PM '06 -0700(MST是UTC的7 小时前)。
例如,以下代码:
t, err := time.Parse("2006-02-01 15:04:05 -0700", "2016-13-03 00:00:00 +0000")
if err != nil {
return err
}
fmt.Println(t.Format("January 2, 2006 at 3:04:05PM MST"))会打印出:
March 13, 2016 at 12:00:00AM UTC虽然用于格式化的日期和时间进行了巧妙的辅助记忆的设计,但依然很难记住,每次用的时候都要查阅(注:1.20中已内置了time.DateTime等常量,如time.DateTime表示2006-01-02 15:04:05)。所幸在 time 包中,最常用的日期和时间格式都有自己的常量。
就像在time.Duration上定义了部分提取的方法一样,对time.Time也定义了类似的方法,包括 Day、Month、Year、Hour、Minute、Second、Weekday、Clock(将time.Time的以单独的小时、分钟和秒int值返回)和Date(将年、月和日以单独的int值返回)。可以使用 After、Before和Equal方法比较两个time.Time实例。
Sub方法返回一个time.Duration,表示两个time.Time实例之间经过的时间,而Add方法返回time.Duration时长之后的time.Time,AddDate方法返回一个新的 time.Time实例,该实例按指定的年、月和日增加。与time.Duration一样,它也定义了Truncate和Round方法。所有这些方法都是在值接收器上定义的,因此它们不会修改time.Time实例。
单调时间
大多数操作系统会追踪两种不同类型的时间:墙上时钟(wall clock),对应于当前时间,和单调时钟(monotonic clock),它是从计算机启动时开始递增。之所以要跟踪两个不同的时钟是因为墙上时间不是统一递增的。夏令时、闰秒和 NTP(网络时间协议)更新可能会导致墙上时间意外地前后移动。这可能会在设置计时器或计算经过的时长时引发问题。
为了解决这个潜在问题,Go 在设置计时器或使用time.Now创建time.Time实例时使用单调时间来记录经过的时间。这种支持是隐式的,计时器会自动使用它。如果两个time.Time实例都设置了单调时间,Sub方法会使用单调时钟来计算time.Duration。如果它们没有设置单调时间(因为其中一个或两个实例没有使用time.Now创建),Sub方法会使用实例中指定的时间来计算time.Duration。
注:如果想了解在未正确处理单调时间时会有什么问题,请参阅Cloudflare博客中详细介绍的早期 Go 版本中由于缺乏单调时间支持而引发的错误的文章。
计时器和超时
正如我们在如何让代码超时中介绍的那样,time包中包含了返回在指定时间后输出值的通道的函数。time.After函数返回一个仅输出一次的通道,而由time.Tick返回的通道在指定的time.Duration间隔后每次输出一个新值。这些与 Go 的并发支持一起使用,以实现超时或定期任务。你还可以使用time.AfterFunc函数在指定的时间间隔后触发某个函数的运行。不要在复杂程序中使用time.Tick,因为底层的time.Ticker无法关闭(因此无法进行垃圾回收)。而应使用time.NewTicker函数,它返回一个*time.Ticker,其中包含要监听的通道,以及重置和停止计时器的方法。
encoding/json
REST API将JSON奉为服务之通信的标准方式,Go 的标准库内置对Go 数据类型与 JSON 之间进行转换的支持。marshaling一词表示从 Go 数据类型转为另一种编码,而unmarshaling表示转换为 Go 数据类型。
使用结构体标签添加元数据
假设我们正在构建一个订单管理系统,并且需要读取和写入以下 JSON:
{
"id":"12345",
"date_ordered":"2020-05-01T13:01:02Z",
"customer_id":"3",
"items":[{"id":"xyz123","name":"Thing 1"},{"id":"abc789","name":"Thing 2"}]
}我们定义映射该数据的类型:
type Order struct {
ID string `json:"id"`
DateOrdered time.Time `json:"date_ordered"`
CustomerID string `json:"customer_id"`
Items []Item `json:"items"`
}
type Item struct {
ID string `json:"id"`
Name string `json:"name"`
}我们使用结构体标签来指定处理JSON数据的规则,也即结构体内字段后面的字符串。尽管结构体标签是用反引号标记的字符串,但它们要放在同一行。结构体标签由一个或多个标签/值对组成,写作tagName:"tagValue",并用空格分隔。由于它们只是字符串,编译器无法验证其格式是否正确,但go vet可以进行验证。此外,请注意这些字段都是导出的。与其他包一样,encoding/json包中的代码无法访问另一个包中结构体的未导出字段。
对于JSON的处理,我们使用标签名json来指定与结构体字段关联的JSON字段的名称。如果没有提供json标签,那么默认行为是假定JSON 对象字段的名称与 Go 结构体字段的名称相匹配。尽管有这种默认行为,即使字段名称相同,最好也使用结构体标签显式指定字段的名称。
注:在将JSON反序列化到没有
json标签的结构体字段时,名称匹配是不区分大小写的。在没有json标签的结构体字段序列化为JSON 时,JSON 字段的首字母始终是大写的,因为该字段是导出的。
如果在序列化或反序列化时需忽略某个字段,对该字段的名称使用破折号(-)。如果该字段在为空时应在输出中省云,可以在名称后添加,omitempty。
警告:“空”定义与零值不完全对齐,可能读者也猜到了。结构体的零值不作为空,但是零长切片或字典则视为空。
结构体标签允许我们使用元数据来控制程序的行为。其他语言,尤其是 Java,鼓励开发人员在各种程序元素上放置注解,来描述应该如何处理它们,而并不明确指定进行处理的方式。虽然声明式编程可以使程序更加简洁,但元数据的自动处理会让程序的行为变得难以理解。任何使用过带有注解的大型 Java 项目的人都会在出现问题时陷入恐慌,因为他们不知道哪段代码正在处理特定的注解以及它做出了什么变化。Go 更偏向于显式的代码而不是短小的代码。结构体标签永远不会自动运行;它们在将结构体实例传递给函数时进行处理。
序列化和反序列化
encoding/json包中的Unmarshal函数用于将字节切片转换为结构体。如果我们有一个名为data的字符串,以下是将data转换为Order类型结构体的代码:
var o Order
err := json.Unmarshal([]byte(data), &o)
if err != nil {
return err
}json.Unmarshal函数将数据填充到一个入参中,就像io.Reader接口的实现一样。这样做有两个原因。首先,像io.Reader的实现一样,这样可对相同的结构体进行高效的重用,从而控制内存使用。其次,没有其它实现的方式。因为Go长时间没有泛型,所以无法指定应该实例化哪种类型来存储正在读取的字节。即使Go添加了泛型,内存使用的优势也依旧存在。
我们使用encoding/json包中的Marshal函数将Order实例以 JSON 的形式写回,并存储在一个字节切片中:
out, err := json.Marshal(o)这带来了一个问题:我们是如何处理结构标签的?你可能还想知道为什么 json.Marshal和json.Unmarshal能够读取和写入任意类型的结构体。毕竟,我们编写的其他方法都只能处理在程序编译时已知的类型(甚至类型开关中列出的类型也是预先枚举的)。这两个问题的答案都是反射。可以在恶龙三剑客:反射、Unsafe 和 Cgo中了解更多关于反射的内容。
JSON、Reader和Writer
json.Marshal和json.Unmarshal函数处理的是字节切片。刚刚也看到了,Go 中的大部分数据源和数据宿都实现了io.Reader和io.Writer接口。虽然可以使用ioutil.ReadAll将io.Reader的全部内容复制到字节切片中,以供json.Unmarshal 读取,但这样做效率低下。同样,我们可以使用json.Marshal将数据写入内存中的字节切片缓冲区,然后将其写入网络或磁盘,但如果我们可以直接写入io.Writer,会更好。
encoding/json包有两种类型供我们处理这些场景。json.Decoder和json.Encoder类型分别从实现了io.Reader和io.Writer接口的任意内容进行读取和写入。让我们快速看一下它们是如何工作的。
我们从一个实现简单结构体的toFile中的数据开始:
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
}
toFile := Person {
Name: "Fred",
Age: 40,
}os.File类型同时实现了io.Reader和io.Writer接口,我们可以使用它来演示json.Decoder和json.Encoder。首先,我们将toFile写入一个临时文件,将临时文件传递给json.NewEncoder,它返回该临时文件的json.Encoder。然后,我们将json.Encoder传递给Encode方法:
tmpFile, err := ioutil.TempFile(os.TempDir(), "sample-")
if err != nil {
panic(err)
}
defer os.Remove(tmpFile.Name())
err = json.NewEncoder(tmpFile).Encode(toFile)
if err != nil {
panic(err)
}
err = tmpFile.Close()
if err != nil {
panic(err)
}写入toFile后,我们可以通过将临时文件的指针传递给json.NewDecoder,并在返回的json.Decoder上调用Decode方法,将其读取为 JSON,并使用类型为Person的变量来接收:
tmpFile2, err := os.Open(tmpFile.Name())
if err != nil {
panic(err)
}
var fromFile Person
err = json.NewDecoder(tmpFile2).Decode(&fromFile)
if err != nil {
panic(err)
}
err = tmpFile2.Close()
if err != nil {
panic(err)
}
fmt.Printf("%+v\n", fromFile)完整示例请见Playground。
JSON数据流编解码
在需要一次读取或写入多个JSON结构体时该怎么办做呢?可以使用我们的老朋友json.Decoder和json.Encoder处理这些情况。
假设有以下数据:
{"name": "Fred", "age": 40}
{"name": "Mary", "age": 21}
{"name": "Pat", "age": 30}对于我们的示例,假设数据存储在一个名为data的字符串中,但它也可以是文件,甚至是传入的HTTP请求(我们稍后会了解HTTP服务端的原理)。
我们将该数据存在到变量t中,每次一个JSON 对象。
和之前一样,我们使用数据源初始化json.Decoder,但这次我们使用json.Decoder的More方法作为for循环条件。这样可以逐个读取数据,每次一个JSON 对象:
var t struct {
Name string `json:"name"`
Age int `json:"age"`
}
dec := json.NewDecoder(strings.NewReader(data))
for dec.More() {
err := dec.Decode(&t)
if err != nil {
panic(err)
}
// process t
}使用json.Encoder写多个值的方式与写单个值的方式相同。本例中,我们写入bytes.Buffer,但任意实现io.Writer接口的类型都可以:
var b bytes.Buffer
enc := json.NewEncoder(&b)
for _, input := range allInputs {
t := process(input)
err = enc.Encode(t)
if err != nil {
panic(err)
}
}
out := b.String()可在Playground中运行本示例。
我们示例数据流中有多个没有封装到数组中的JSON 对象,但读者也可以使用json.Decoder从数组中读取单个对象,而无需一次性将整个数组加载到内存中。这可以大幅提升性能并减少内存使用。在Go文档中有一个示例。
自定义JSON 解析
虽然默认功能通常已足够使用,但有时需要进行重载。尽管time.Time默认支持 RFC 339 格式的 JSON 字段,但可能需要处理其他时间格式。我们可以通过创建一个实现json.Marshaler和json.Unmarshaler两个接口的新类型来进行处理:
type RFC822ZTime struct {
time.Time
}
func (rt RFC822ZTime) MarshalJSON() ([]byte, error) {
out := rt.Time.Format(time.RFC822Z)
return []byte(`"` + out + `"`), nil
}
func (rt *RFC822ZTime) UnmarshalJSON(b []byte) error {
if string(b) == "null" {
return nil
}
t, err := time.Parse(`"`+time.RFC822Z+`"`, string(b))
if err != nil {
return err
}
*rt = RFC822ZTime{t}
return nil
}我们将一个time.Time实例内嵌到名为RFC822ZTime的新结构体中,这样仍可以访问time.Time的其他方法。就像我们在指针接收器和值接收器中讨论的那样,读取时间值的方法对值接收器声明,而修改时间值的方法对指针接收器声明。
然后,我们更改了DateOrdered字段的类型,可使用 RFC 822 格式的时间进行操作:
type Order struct {
ID string `json:"id"`
DateOrdered RFC822ZTime `json:"date_ordered"`
CustomerID string `json:"customer_id"`
Items []Item `json:"items"`
}可在Playground中运行这段代码。
这种方法存在一个缺点:JSON的日期格式决定了数据结构中字段的类型。这是encoding/json方案本身的不足。可以让Order实现json.Marshaler和json.Unmarshaler,但那会要求你编写代码处理所有字段,包括那些不需要自定义支持的字段。结构体标签格式没有提供指定函数来解决具体字段的方式。这样我们就得为该字段创建一个自定义类型了。
另一种方式在Ukiah Smith的博客文章中进行了描述。我们可以只重新定义不符合默认序列化行为的字段,利用到结构体内嵌所做的 JSON 序列化和反序列化(我们在使用内嵌实现组合中进行了讲解)。如果嵌套结构体的字段名与外层结构体中的相重复,在序列化和反序列化时就会忽略该字段。
本例中,Order中的字段如下:
type Order struct {
ID string `json:"id"`
Items []Item `json:"items"`
DateOrdered time.Time `json:"date_ordered"`
CustomerID string `json:"customer_id"`
}MarshalJSON方法如下:
func (o Order) MarshalJSON() ([]byte, error) {
type Dup Order
tmp := struct {
DateOrdered string `json:"date_ordered"`
Dup
}{
Dup: (Dup)(o),
}
tmp.DateOrdered = o.DateOrdered.Format(time.RFC822Z)
b, err := json.Marshal(tmp)
return b, err
}在Order的MarshalJSON方法中,我们定义了底层类型为Order的Dup类型。创建Dup的原因是基于其它类型的类型具有和底层类型相同的字段,但方法却不同。如果没有Dup,在调用json.Marshal时就会进入到对MarshalJSON的无限调用循环,最终导致栈溢出。
我们定义了一个包含DateOrdered字段并内嵌Dup的匿名结构体。然后将Order实例赋给tmp中的内嵌字段,将tmp中的DateOrdered字段赋值为时间格式RFC822Z,对tmp调用json.Marshal。这会生成所需的JSON输出。
UnmarshalJSON中的逻辑类似:
func (o *Order) UnmarshalJSON(b []byte) error {
type Dup Order
tmp := struct {
DateOrdered string `json:"date_ordered"`
*Dup
}{
Dup: (*Dup)(o),
}
err := json.Unmarshal(b, &tmp)
if err != nil {
return err
}
o.DateOrdered, err = time.Parse(time.RFC822Z, tmp.DateOrdered)
if err != nil {
return err
}
return nil
}在UnmarshalJSON中,json.Unmarshal调用o中字段(DateOrdered除外),因为它嵌套在tmp之中。解封后通过使用time.Parse处理tmp中的DateOrdered字段来反序列化o中的DateOrdered。
可在The Go Playground 中运行这段代码。
虽然这样可以让Order中的一个字段不必绑定JSON格式,但Order的MarshalJSON和UnmarshalJSON方法就与JSON中时间字段的格式发生了耦合。我们无法复用Order去支持其它时间格式的JSON。
为限制考虑JSON处理方式的代码量,定义两个不同的结构体。一个用于和JSON之间的转换,另一个用于数据数据。将JSON读入适配JSON的类型,然后拷贝至另一个类型。在写入JSON时,执行相反操作。这确实会导致一定的重复,但这会保持业务逻辑不依赖于连接协议。
可以将map[string]any传递给json.Marshal和json.Unmarshal来在JSON和Go之间进行转换,但把它用于代码的解释阶段,在清楚如何进行处理后替换为具体的类型。Go使用类型是有原因的,它表明了预期的数据及其类型。
虽然JSON是标准库中最常用的的编码器,Go还内置了其它编码器,如XML和Base64。如果你需要编码的数据格式无法在标准库或第三方库中找到支持,可以自行编写。我们会在使用反射编写数据序列化工具中学习到如何实现自己的编码器。
警告:标准库中内置了encoding/gob,这是针对Go的二进制表现,有点类似于Java的序列化。正如Java的序列化是Enterprise Java Beans和Java RMI的连接协议一样,gob协议用于net/rpc包中实现的Go RPC(远程过程调用)的连接格式。不要使用encoding/gob或net/rpc。如果你希望通过Go做远程方法调用,使用GRPC等标准协议,这样就限于某一种语言。不管你有多爱Go语言,如果希望服务有价值的话,就允许开发者使用其它语言调用它。
本文来自正在规划的Go语言&云原生自我提升系列,欢迎关注后续文章。